CLONE: Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
Abstract
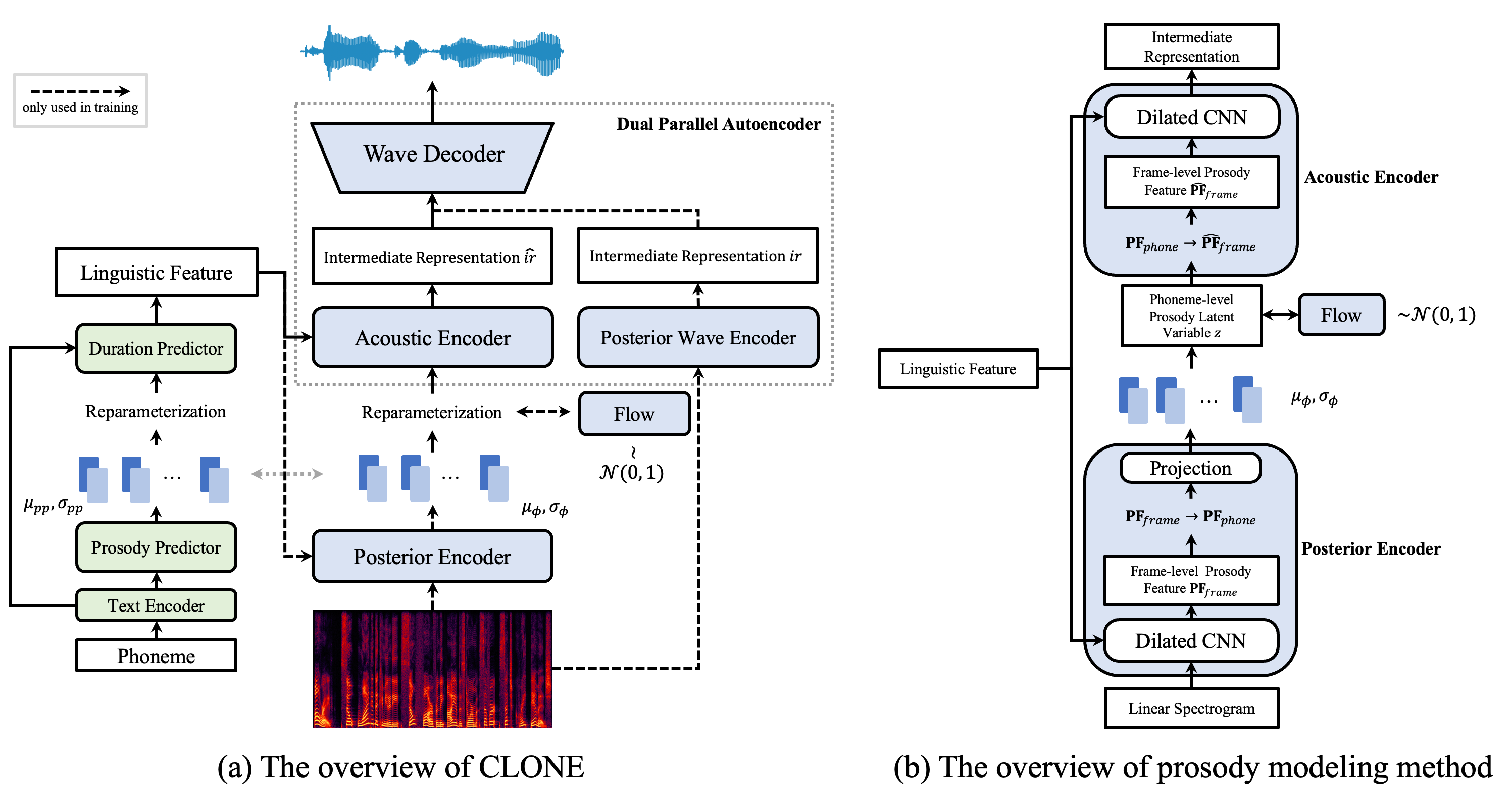
Some recent studies have demonstrated the feasibility of single-stage neural text-to-speech, which does not need to generate mel-spectrograms but generates the raw waveforms directly from the text. Single-stage text-to-speech often faces two problems: a) the one-to-many mapping problem due to multiple speech variations and b) insufficiency of high frequency reconstruction due to the lack of supervision of ground-truth acoustic features during training. To solve the a) problem and generate more expressive speech, we propose a novel phoneme-level prosody modeling method based on a variational autoencoder with normalizing flows to model underlying prosodic information in speech. We also use the prosody predictor to support end-to-end expressive speech synthesis. Furthermore, we propose the dual parallel autoencoder to introduce supervision of the ground-truth acoustic features during training to solve the b) problem enabling our model to generate high-quality speech. We compare the synthesis quality with state-of-the-art text-to-speech systems on an internal expressive English dataset. Both qualitative and quantitative evaluations demonstrate the superiority and robustness of our method for lossless speech generation while also showing a strong capability in prosody modeling.
MOS Sample (Section 4.5.1)
| text | VITS | FastSpeech 2 + TFGAN | Tacotron 2 + TFGAN | CLONE without MBD | CLONE |
|---|---|---|---|---|---|
| He’s still so hang up on his dead dog that no one can persuade him to eat. | |||||
| Yes, we should try to contact more. | |||||
| Oh, we’ve a lot to learn. | |||||
| Do you know the way to Melbourne? | |||||
| I like the traditions very much. | |||||
| Well, I’ll restart the machine and hope for the best. | |||||
| He is learning to ride a bicycle. | |||||
| I’m not sure about that, we’d better ask the lady there. | |||||
| Have you ever received any vaccination? | |||||
| Can you tell me where to alter my suits in the downtown? |
CMOS Sample (Section 4.5.1)
| text | 48 kHz Recording | 24 kHz VITS | 24 kHz CLONE | 48 kHz CLONE |
|---|---|---|---|---|
| So that’s where we should be looking to discover. | ||||
| Perhaps it is no wonder people are happy to see him. | ||||
| Maybe you crave a good burger now and again. | ||||
| We had a taco party at my friend’s house, and I invited all these people. | ||||
| I usually stick to a more natural red shade, but every once in a while I can’t resist going blue. |
Prosody Variation (Section 4.5.2 - Prosody Variation)
| Sample from -1 | Sample from 1 |
|---|---|
Prosody Transfer (Section 4.5.2 - Prosody Transfer)
| End-to-end Synthesis | Transfer Result | Reference |
|---|---|---|
Prosody Reconstruction (Section 4.5.2 - Prosody Reconstruction)
| Reconstruction Result | Reference |
|---|---|
Prosody Predictor Transfer
By replacing the speaker id of the prosody predictor, we can use the prosody of different speaker to synthesize the sound of the same timbre.
| Speaker A | Speaker A with Prosody Predictor of Speaker B | Speaker B |
|---|---|---|